
Stell dir vor, du betreibst einen Online-Shop: Eine Kundin gibt eine Bestellung auf und plötzlich müssen mehrere Systeme gleichzeitig reagieren. E-Mails werden verschickt, der Lagerbestand aktualisiert, die Zahlung verarbeitet.
Wie sorgt man dafür, dass all diese Prozesse zuverlässig und skalierbar ablaufen, ohne dass die Systeme direkt voneinander abhängen?
Die Antwort: Apache Kafka.
Im Folgenden schauen wir uns an, wie Kafka funktioniert, welche zentralen Konzepte dahinterstecken und wann sich der Einsatz wirklich lohnt.
- Was ist Apache Kafka?
- Zentrale Konzepte
- Wie funktioniert Kafka?
- Wann solltest du Kafka einsetzen?
- Wann solltest du Kafka eher nicht einsetzen?
- Typische Anwendungsfälle und Patterns
- Herausforderungen und typische Fallstricke
- Fazit
- FAQ: Kafka
Was ist Apache Kafka?
Apache Kafka ist ein verteilter Event-Streaming-Dienst. Er ermöglicht es dir große Datenmengen in Echtzeit zu verarbeiten und zuverlässig zwischen Systemen auszutauschen.
Statt Daten nur punktuell zu übertragen, werden Ereignisse, sogenannte Events, kontinuierlich als Datenstrom gespeichert. Das macht Kafka besonders interessant für moderne Architekturen, in denen viele Systeme miteinander interagieren, etwa bei Microservices, Datenpipelines oder Echtzeit-Analysen.
Zentrale Konzepte
Damit du Kafka verstehen kannst, reichen ein paar zentrale Bausteine:
- Broker: Ein Kafka-Broker ist der Server im Cluster. Er speichert Topics und Partitionen und stellt Daten für Producer und Consumer bereit.
- Cluster: Ein Kafka-Cluster besteht aus mehreren Brokern, die gemeinsam Daten speichern und verarbeiten. So kann Kafka Daten verteilen, skalieren und ausfallsicher betreiben.
- Topic: Ein Topic ist ein benannter Datenstrom in Kafka. Die Nachrichten werden dort dauerhaft als Log gespeichert und in der Reihenfolge ihres Eingangs angehängt.
- Producer: Ein Producer ist ein Client, der Daten an Kafka sendet. Er schreibt Events in ein Topic.
- Consumer: Ein Consumer ist ein Client, der Daten aus Kafka liest. Er empfängt und verarbeitet die Events aus einem Topic.
- Partition: Ein Topic besteht aus mehreren Partitionen. Dadurch kann Kafka Daten parallel auf mehrere Broker verteilen und hohe Performance sowie Skalierbarkeit erreichen.
- Replication: Partitionen können auf mehrere Broker repliziert werden. Das erhöht die Ausfallsicherheit, weil bei einem Broker-Ausfall weiterhin Kopien der Daten verfügbar sind.
Kafka erreicht seine hohe Performance und Ausfallsicherheit durch ein Zusammenspiel dieser zentralen Konzepte.
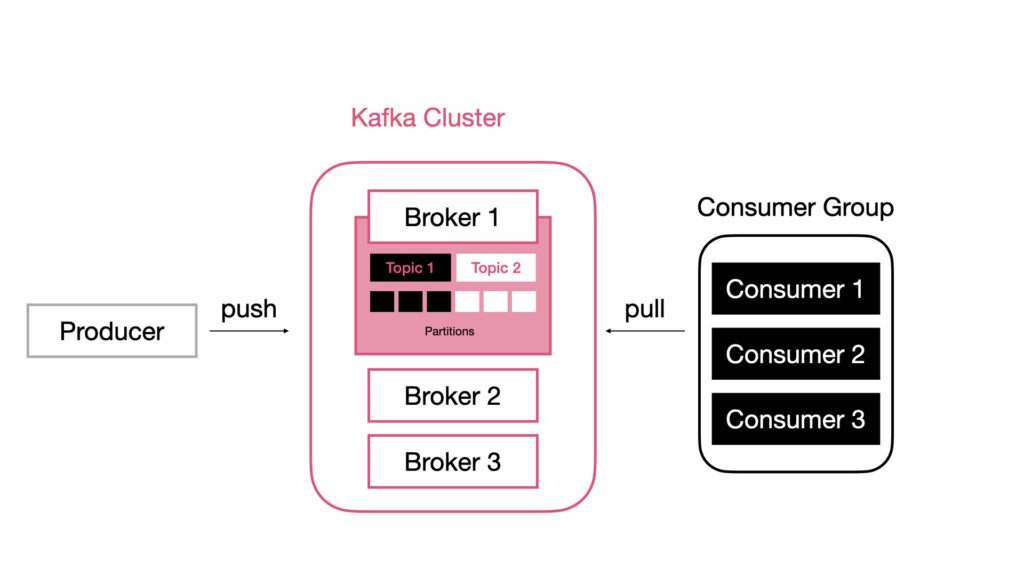
Wie funktioniert Kafka?
Im Kern basiert Kafka auf einem einfachen Prinzip: einem fortlaufenden Log.
Innerhalb einer Partition werden Events strikt der Reihe nach gespeichert. Neue Nachrichten werden einfach am Ende angehängt. Dieses sequenzielle Schreiben ist extrem effizient und einer der Hauptgründe für die hohe Performance von Kafka.
Da ein Topic aus mehreren Partitionen besteht, können Producer Daten parallel schreiben, während Consumer sie parallel lesen.
Gleichzeitig sorgt die Replikation dafür, dass jede Partition mehrfach vorhanden ist. Ein Leader verarbeitet dabei die Anfragen, während Follower die Daten synchron halten. Fällt der Leader aus, übernimmt automatisch ein Follower.
Consumer Groups
Sobald du mehrere Consumer nutzen willst, wird das Konzept der Consumer Groups wichtig. Consumer können sich zu Gruppen zusammenschließen, um gemeinsam Daten zu verarbeiten.
Innerhalb einer solchen Gruppe wird jede Partition genau einem Consumer zugewiesen. Dadurch wird die Last automatisch verteilt und die Verarbeitung kann horizontal skaliert werden.
Für dich bedeutete das: Je mehr Partitionen und Consumer vorhanden sind, desto mehr Parallelität ist möglich.
Beispiel
Ein Topic hat 3 Partitionen und du hast 3 Consumer in einer Gruppe:
- Consumer A → Partition 0
- Consumer B → Partition 1
- Consumer C → Partition 2
Jeder Consumer verarbeitet nur „seine“ Partition.
Fügst du einen vierten Consumer hinzu, bleibt einer zunächst ohne Arbeit, weil es nur 3 Partitionen gibt.
Offsets
Kafka löscht seine Daten nicht einfach. Deshalb braucht jeder Consumer eine Möglichkeit, sich seine Position im Datenstrom zu merken. Dafür gibt es Offsets.
Ein Offset ist im Grunde ein Zeiger innerhalb einer Partition. Er gibt an, welche Nachricht als Nächstes gelesen wird.
Jeder Consumer verwaltet dieses Offset selbst, weshalb mehrere Consumer den selben Datenstrom unabhängig voneinander lesen können.
Das ermöglicht dir auch sogenannten Replays: das erneute Verarbeiten von Daten zu einem späteren Zeitpunkt.
Beispiel
Stell dir eine Partition wie eine fortlaufende Liste vor:
- Nachricht 1 → Offset 0
- Nachricht 2 → Offset 1
- Nachricht 3 → Offset 2
Ein Consumer hat zuletzt Offset 1 verarbeitet. Beim nächsten Start weiß er: „Ich mache bei Offset 2 weiter.“
So kann er genau dort weiterlesen, wo er aufgehört hat.
Wie lange bleiben Daten erhalten?
Im Gegensatz zu klassischen Message Queues löscht Kafka die Daten nicht sofort nach dem Lesen. Stattdessen bleiben Events für eine definierte Zeit oder bis zu einer bestimmten Datenmenge gespeichert. Alternativ kann Kafka Topics auch kompaktieren, sodass nur der letzte Wert pro Schlüssel erhalten bleibt.
Diese Retention macht Kafka besonders nützlich für Analyse-Workloads oder Systeme, die Daten später erneut verarbeiten müssen.
Reihenfolge und Partitionierung
Innerhalb einer einzelnen Partition garantiert Kafka die Reihenfolge von Events. Welche Events in welcher Partition landen, hängt häufig von einem Schlüssel (Key) ab. Events mit demselben Key werden in dieselbe Partition geschrieben und bleiben dadurch in der richtigen Reihenfolge.
Eine globale Reihenfolge über alle Partitionen hinweg gibt es hingegen nicht.
Zustellgarantien
Je nach Konfiguration kannst du unterschiedliche Zustellgarantien wählen.
- Bei at most once können Nachrichten verloren gehen
- Bei at least once können sie doppelt verarbeitet werden
- Exactly once vermeidet beides, ist aber deutlich komplexer umzusetzen.
Welche Variante sinnvoll ist, hängt stark von deinem jeweiligen Anwendungsfall ab.
Unterschied zu klassischen Message Queues
Auch wenn Kafka auf den ersten Blick wie eine klassische Message Queue wirkt, unterscheidet es sich grundlegend davon.
Während Systeme wie RabbitMQ Nachrichten nach der Verarbeitung löschen, speichert Kafka alle Events dauerhaft in einem Log. Dadurch können Daten mehrfach gelesen oder zu einem späteren Zeitpunkt erneut verarbeitet werden.
Kafka ist deshalb weniger eine Queue und eher ein verteiltes, persistentes Event-Log.
Wann solltest du Kafka einsetzen?
Kafka spielt seine Stärken vor allem dann aus, wenn viele Systeme miteinander interagieren und große Datenmengen kontinuierlich verarbeitet werden müssen.
Typische Einsatzszenarien sind Event-Streaming, Microservices-Architekturen oder Datenpipelines. Besonders wertvoll ist Kafka, wenn mehrere Konsumenten gleichzeitig auf dieselben Daten zugreifen oder wenn Daten später erneut verarbeitet werden sollen.
Ein klassisches Beispiel ist ein Online-Shop: Eine Bestellung wird als Event in Kafka geschrieben. Verschiedene Services, etwa für E-Mail, Lagerbestand oder Versand, reagieren unabhängig darauf. Fällt ein Service aus, kann er die Events später einfach nachholen.
Wann solltest du Kafka eher nicht einsetzen?
Trotz seiner Stärken ist Kafka nicht immer die richtige Lösung.
- Für einfache Kommunikation zwischen wenigen Systemen ist Kafka oft unnötig komplex.
- Auch wenn niedrige Latenz für synchrone Anfragen entscheidend ist
- oder nur kleine Datenmengen verarbeitet werden, sind einfachere Alternativen meist besser geeignet.
Hinzu kommt der Betriebsaufwand: Ein Kafka-Cluster musst du konfigurieren, überwachen und skalieren.
Typische Anwendungsfälle und Patterns
In der Praxis wirst du Kafka selten isoliert einsetzen, sondern als Teil größerer Architekturen.
- Beim Event Sourcing werden alle Änderungen als Events gespeichert, sodass sich der Zustand eines Systems jederzeit rekonstruieren lässt.
- Beim Stream Processing werden Daten direkt während des Flusses verarbeitet, zum Beispiel gefiltert oder aggregiert.
- Und mit Tools wie Kafka Connect lassen sich unterschiedlichste Systeme miteinander verbinden.
Herausforderungen und typische Fallstricke
So mächtig Kafka ist, bringt es auch einige Herausforderungen mit sich.
- Der Betrieb eines Clusters ist nicht trivial, und auch die Datenmodellierung wird oft unterschätzt.
- Events sollten stabil und versioniert sein, da sie von vielen Konsumenten genutzt werden.
- Ein weiterer häufiger Stolperstein ist die Annahme einer globalen Reihenfolge. Tatsächlich gilt diese nur innerhalb einzelner Partitionen.
Fazit
Kafka ist ein leistungsfähiges Werkzeug für moderne Datenarchitekturen, aber kein Allheilmittel. Es lohnt sich vor allem dann, wenn du echte Event-Streams, Skalierung und Entkopplung brauchst.
FAQ: Kafka
Kafka ist ein verteiltes System, das Daten als kontinuierlichen Ereignisstrom (Event-Stream) speichert und verarbeitet. Es ermöglicht, dass mehrere Systeme gleichzeitig auf dieselben Daten zugreifen, ohne direkt miteinander verbunden zu sein.
Nicht ganz. Kafka funktioniert eher wie ein persistentes Log, in dem Daten gespeichert bleiben. Im Gegensatz zu klassischen Message Queues können Nachrichten mehrfach gelesen und später erneut verarbeitet werden.
Kafka eignet sich besonders bei vielen Systemen, großen Datenmengen und Echtzeitverarbeitung. Typische Szenarien sind Microservices, Event-Streaming und Datenpipelines.
Eine Consumer Group ist eine Gruppe von Consumern, die gemeinsam ein Topic lesen. Dabei wird jede Partition genau einem Consumer zugewiesen, um die Last zu verteilen.
Offsets sind Positionsmarker innerhalb einer Partition. Sie geben an, welche Nachricht ein Consumer als Nächstes liest.
Kafka speichert Daten je nach Konfiguration für eine bestimmte Zeit oder bis zu einer maximalen Größe. Alternativ kann eine Kompaktierung aktiviert werden, bei der nur der letzte Wert pro Schlüssel erhalten bleibt.
Quelle Titelbild: kostenlose Hintergrundfotos von .pngtree.com und Apache Kafka Logo



